Formato de datos masivos
En ecosistemas como Hadoop y Spark, la elección del formato de datos impacta directamente en:
- Rendimiento de lectura/escritura: Los formatos binarios son generalmente más rápidos que los de texto
- Costo de almacenamiento: Un formato bien elegido puede reducir el tamaño en disco entre un 50-90%
- Velocidad de consultas: Los formatos columnares optimizan las consultas analíticas
- Interoperabilidad: Algunos formatos funcionan mejor con herramientas específicas
Propiedades Fundamentales
Section titled “Propiedades Fundamentales”Todo formato de datos utilizado en Big Data debe satisfacer las siguientes propiedades:
-
Independencia del lenguaje El formato debe ser agnóstico respecto al lenguaje de programación utilizado. Un archivo serializado en Python debe poder deserializarse en Java o Scala sin problemas.
-
Expresividad Debe soportar estructuras complejas y anidadas. No todos los formatos pueden representar objetos complejos o arrays multidimensionales.
-
Eficiencia Busca un equilibrio entre velocidad de acceso y tamaño reducido del fichero. Los datos no deben tardar mucho en procesarse ni ocupar demasiado espacio.
-
Dinamismo Los programas deben poder procesar y definir nuevos tipos de datos. La evolución del esquema es crítica en Big Data, donde los datos cambian constantemente.
-
Formato standalone y divisible El fichero debe ser divisible en fragmentos (splittable) para que herramientas como Hadoop/Spark puedan procesarlo en paralelo. Esto es imprescindible para cualquier análisis distribuido.
-
Soporte para compresión Debe permitir comprimir los datos sin perder capacidad de procesamiento paralelo.
Formatos
Section titled “Formatos”| Formato | Velocidad | Tamaño | Expresividad | Ejemplos |
|---|---|---|---|---|
| Texto plano | Lenta | Grande | Media | CSV, XML, JSON |
Ventajas:
- Fácil de inspeccionar y debuggear
- Buena interoperabilidad
- No requiere librerías especializadas
Desventajas:
- Ocupan más espacio
- Procesamiento más lento
- Menos eficientes para análisis
Binarios
Section titled “Binarios”| Formato | Velocidad | Tamaño | Expresividad | Arquitectura |
|---|---|---|---|---|
| Avro | Rápida | Medio | Alta | Basado en filas |
| Parquet | Rápida | Muy pequeño | Alta | Basado en columnas |
| ORC | Rápida | Muy pequeño | Alta | Basado en columnas |
Ventajas:
- Mejor rendimiento
- Tamaño reducido
- Serialización compacta
Desventajas:
- Requieren librerías especializadas
- Menos legibles directamente
- Más complejos de implementar
Filas vs Columnas
Section titled “Filas vs Columnas”Esta es una de las decisiones más importantes al elegir un formato de datos.
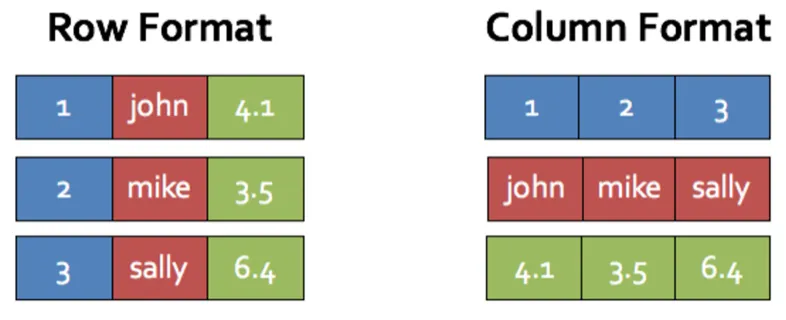
Almacenamiento Orientado a Filas
Section titled “Almacenamiento Orientado a Filas”En formatos basados en filas como CSV, XML o JSON, cada registro se almacena en una fila o documento completo.
JSON tradicional (JSON Lines):
{ "empleados": [ { "nombre": "Carlos", "altura": 180, "edad": 44 }, { "nombre": "Juan", "altura": 175, "edad": null } ]}JSONL (JSON Lines - un objeto por línea):
{"nombre": "Carlos", "altura": 180, "edad": 44}{"nombre": "Juan", "altura": 175, "edad": null}JSONL es preferible en Big Data porque permite procesar línea a línea sin cargar el fichero completo en memoria.
| Aspecto | Descripción |
|---|---|
| Acceso a registros | Acceso rápido a todos los campos de un registro |
| Escritura | Operación simple: añadir una nueva línea |
| Consultas analíticas | Lento si solo necesitas unas pocas columnas |
| Compresión | Menos eficiente (datos heterogéneos no se comprimen bien) |
| OLTP | Excelente para operaciones transaccionales |
Almacenamiento Orientado a Columnas
Section titled “Almacenamiento Orientado a Columnas”En formatos columnares, cada columna se almacena en su conjunto de ficheros. Todos los datos de la misma columna se agrupan contiguamente.
Representación conceptual:
Datos en filas:┌─────────────────────────────────┐│ ID │ Nombre │ Salario │ Ciudad │├────┼─────────┼─────────┼────────┤│ 1 │ Carlos │ 50000 │ Madrid ││ 2 │ Juan │ 45000 │ BCN ││ 3 │ María │ 52000 │ Vale │└────┴─────────┴─────────┴────────┘
Datos en columnas (Parquet):ID: [1, 2, 3]Nombre: [Carlos, Juan, María]Salario: [50000, 45000, 52000]Ciudad: [Madrid, BCN, Vale]| Aspecto | Descripción |
|---|---|
| Acceso selectivo | Rápido si solo necesitas unas columnas |
| Compresión | Excelente (datos del mismo tipo se comprimen bien) |
| Escritura | Lenta y compleja (requiere reescribir múltiples archivos) |
| Consultas analíticas | Excepcional (OLAP) |
| Actualizaciones | Muy costosas computacionalmente |
| OLAP | Perfecto para análisis complejos |
Desventajas de los formatos columnares:
- Acceso a registros individuales: Para recuperar un registro completo, debe reconstruirse leyendo datos de varios archivos de columnas
- Actualizaciones: Requiere descomprimir, modificar, recomprimir y escribir nuevamente
- Cargas transaccionales: No son apropiados para OLTP
Estrategias de optimización: Los formatos columnares dividen los datos mediante particionado y clustering, organizándolos según patrones de consulta y modificación, reduciendo así la sobrecarga.
Apache Avro
Section titled “Apache Avro”Apache Avro es un formato de almacenamiento basado en filas que combina la velocidad de los formatos binarios con la flexibilidad de esquemas definidos.
El formato Avro se basa en el uso de esquemas, los cuales definen los tipos de datos y protocolos mediante JSON. Cuando los datos .avro son leídos siempre está presente el esquema con el que han sido escritos.
Formato
Section titled “Formato”Cada fichero Avro almacena el esquema en la cabecera del fichero y luego están los datos en formato binario. Los esquemas se componen de tipos primitivos (null, boolean, int, long, float, double, bytes, y string) y compuestos (record, enum, array, map, union, y fixed).
Ejemplo de esquema (empleado.avsc):
{ "type": "record", "namespace": "EduardoPrimo", "name": "Empleado", "fields": [ { "name": "nombre", "type": "string" }, { "name": "altura", "type": "int" }, { "name": "edad", "type": ["null", "int"], "default": null } ]}Ejemplo de uso
Section titled “Ejemplo de uso”Existen dos librerías para trabajar con avro avro-python3 y fastavro, vamos a utilizar fastavro por su mayor velocidad para trabajar con datasets grandes.
pip install fastavroimport fastavro
# Leer esquemaschema = { "type": "record", "namespace": "EduardoPrimo", "name": "Empleado", "fields": [ {"name": "nombre", "type": "string"}, {"name": "altura", "type": "int"}, {"name": "edad", "type": ["null", "int"], "default": None} ]}
schemaParseado = fastavro.parse_schema(schema)
empleados = [ {"nombre": "Carlos", "altura": 180, "edad": 44}, {"nombre": "Juan", "altura": 175, "edad": None}]
# Escribir con Fastavrowith open('empleadosf.avro', 'wb') as f: fastavro.writer(f, schemaParseado, empleados)
# Leer con Fastavrowith open("empleadosf.avro", "rb") as f: reader = fastavro.reader(f) empleados_leidos = [e for e in reader]Integración con HDFS
Section titled “Integración con HDFS”⚠️ Pendiente de revisar
from hdfs import InsecureClientfrom hdfs.ext.avro import AvroWriterfrom hdfs.ext.dataframe import write_dataframe
# Conectar a HDFShdfs_client = InsecureClient('http://iabd-virtualbox:9870')
# Leer desde HDFSwith hdfs_client.read('/user/iabd/pdi_sales.csv') as reader: df = pd.read_csv(reader, sep=';')
# Persistir en HDFSwith AvroWriter(hdfs_client, '/user/iabd/sales.avro', schemaParseado) as aw: for record in df.to_dict('records'): aw.write(record)
# O más fácil con write_dataframewrite_dataframe(hdfs_client, '/user/iabd/sales.avro', df, schema=schemaParseado)Apache Parquet
Section titled “Apache Parquet”Apache Parquet es un formato de almacenamiento basado en columnas diseñado específicamente para el ecosistema Big Data, con soporte en Hadoop, Spark y prácticamente todos los frameworks de procesamiento de datos modernos.
| Aspecto | Valor |
|---|---|
| Tipo | Binario basado en columnas |
| Compresión | ~75% con Snappy, ~85% con Gzip |
| Splittable | Sí |
| Auto-descriptivo | Sí (contiene esquema embebido) |
| Ecosistema | Spark, Hadoop, Presto, Athena |
| Ideal para | Consultas analíticas (OLAP) |
Ventaja clave: Los metadatos se almacenan al final, permitiendo escrituras rápidas en una única pasada.
Ejemplo de uso
Section titled “Ejemplo de uso”PyArrow es la librería estándar para trabajar con Parquet:
pip install pyarrowimport pyarrow.parquet as pqimport pyarrow as pa
# Definir esquemaschema = pa.schema([ ('nombre', pa.string()), ('altura', pa.int32()), ('edad', pa.int32())])
# Crear datos en formato de columnasempleados = { "nombre": ["Carlos", "Juan"], "altura": [180, 44], "edad": [44, 34]}
# Crear tabla Arrow y escribir en Parquettabla = pa.Table.from_pydict(empleados, schema)pq.write_table(tabla, 'empleados.parquet')
# Leer el ficherotable2 = pq.read_table('empleados.parquet')print(table2)Integración con HDFS
Section titled “Integración con HDFS”⚠️ Pendiente de revisar
# Asumiendo que core-site.xml contiene:# <property># <name>fs.defaultFS</name># <value>hdfs://iabd-virtualbox:9000</value># </property>
df.to_parquet('hdfs://iabd-virtualbox:9000/sales.parquet')Apache ORC
Section titled “Apache ORC”Apache ORC (Optimized Row Columnar) es un formato columnar optimizado específicamente para Hive y ecosistemas analíticos.
| Aspecto | Valor |
|---|---|
| Tipo | Binario basado en columnas |
| Compresión | Usa Zlib (muy alta) |
| Optimizado para | Hive y HiveQL |
| Tipos de datos | Soporta tipos simples y complejos de Hive |
| Estructura | Stripes (tiras de datos) |
Uso con PyArrow
Section titled “Uso con PyArrow”pip install pandasimport pandas as pdimport pyarrow as paimport pyarrow.orc as orcfrom io import StringIO
# Datos CSV en una variablecsv_data = """Country;Zip;SalesGermany;12345;1000Germany;54321;2000France;75001;1500Germany;10115;3000"""
# Leer CSV desde la variabledf = pd.read_csv(StringIO(csv_data), sep=';')
# Limpiar datos# Convertir Zip a string y eliminar espaciosdf['Zip'] = df['Zip'].astype(str).str.strip()# Nos quedamos con las filas que el país es Germanydf = df[df.Country == "Germany"]
# Convertir a tabla Arrowtable = pa.Table.from_pandas(df, preserve_index=False)
# Escribir ORCorc.write_table(table, 'pdi_sales.orc')Compresión de Datos
Section titled “Compresión de Datos”La compresión es crítica en Big Data. Busca redundancia y repetición en los datos, recodificándolos para reducir tamaño.
-
Menor espacio en disco y almacenamiento cloud
-
Menos transmisión de datos a través de la red
-
Lectura más rápida (menos I/O)
-
Costo: Compresión y descompresión consumen CPU
Algoritmos de compresión principales
Section titled “Algoritmos de compresión principales”| Algoritmo | Velocidad | Compresión | Caso de uso |
|---|---|---|---|
| Gzip | Media | Media | General |
| Bzip2 | Lenta | Alta | Almacenamiento a largo plazo |
| Snappy | Alta | Media | Big Data (Hadoop/Spark) |
| Zlib | Media | Media | Predeterminado en ORC |
Para Big Data: Snappy es la opción típica porque prioriza velocidad sobre tamaño.
Ejemplo
Section titled “Ejemplo”pip install python-snappyfrom fastavro import writer, parse_schema
# Sin compresión (por defecto)writer(f, schemaParseado, records)
# Con Gzip (deflate)writer(f, schemaParseado, records, 'deflate')
# Con Snappy (recomendado)writer(f, schemaParseado, records, 'snappy')import pandas as pd
# Con Parquetdf.to_parquet('datos.parquet') # Por defecto comprimido
# Con ORCdf.to_orc('datos.orc', engine_kwargs={"compression": 'zlib'})Impacto de la compresión (ejemplo real)
Section titled “Impacto de la compresión (ejemplo real)”Archivo de 100GB, sin compresión: ~100GB
| Algoritmo | Tamño final | Porcentaje |
|---|---|---|
| Sin compresión | 6.9 MiB | 100% |
| Gzip | 1.9 MiB | 27% |
| Snappy | 2.8 MiB | 41% |
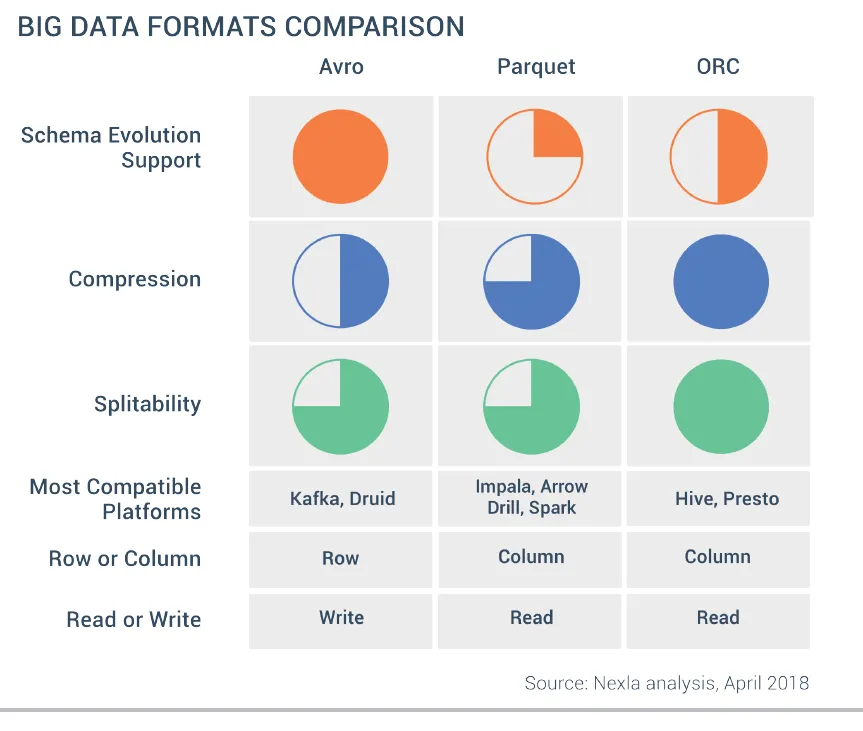
Comparativa de Formatos
Section titled “Comparativa de Formatos”Tabla de características
Section titled “Tabla de características”| Característica | CSV | JSON | Avro | Parquet | ORC |
|---|---|---|---|---|---|
| Independencia lenguaje | ✔ | ✔ | ✔ | ✔ | ✔ |
| Expresivo | ✗ | ✔ | ✔ | ✔ | ✔ |
| Eficiente | ✗ | ✗ | ✔ | ✔✔ | ✔✔ |
| Dinámico/Flexible | ✗ | ✗ | ✔✔ | ✔ | ✔ |
| Legible | ✔✔ | ✔ | ✗ | ✗ | ✗ |
| Divisible | ✔ | ✗ | ✔ | ✔ | ✔ |
| Compresión | ✗ | ✗ | ✔ | ✔✔ | ✔✔ |
Matriz de decisión
Section titled “Matriz de decisión”| Necesidad | Recomendación | Justificación |
|---|---|---|
| Escritura rápida de nuevos datos | Avro o CSV | Avro y CSV permiten escritura rápida y sencilla de nuevos registros. |
| Análisis de columnas específicas | Parquet o ORC | Formatos columnares optimizan consultas sobre columnas específicas. |
| Evolución de esquema frecuente | Avro | Avro facilita la evolución de esquemas y versionado. |
| Trabajas con Hive/HiveQL | ORC | ORC está optimizado para Hive y HiveQL. |
| Trabajas con Spark y análisis | Parquet | Parquet tiene soporte nativo y excelente rendimiento en Spark. |
| Usas Kafka como fuente | Avro | Avro es el estándar en Kafka para serialización y evolución de esquemas. |
| Máxima compresión | Parquet o ORC | Parquet y ORC ofrecen altos ratios de compresión con Gzip/Zlib. |
| Datos con estructuras complejas anidadas | Parquet | Parquet soporta mejor estructuras anidadas y complejas. |
Tabla comparativa
Section titled “Tabla comparativa”| Característica | Avro | Parquet | ORC |
|---|---|---|---|
| Almacenamiento | Filas | Columnas | Columnas |
| Escritura | Rápida | Lenta | Lenta |
| Lectura/Análisis | Lenta (filas) | Rápida (columnas) | Rápida (columnas) |
| Compresión | Media | Alta (75-85%) | Alta (Zlib) |
| Evolución esquema | Excelente | Media | Media |
| Integración | Kafka, Hadoop, Streaming | Spark, Presto, Athena | Hive, HiveQL |
| Estructuras anidadas | Sí | Sí (mejor soporte) | Sí |
| Debugging | Fácil | Difícil | Difícil |
| Casos de uso | Streaming, logs, ingestión | Análisis, BI, OLAP | Hive, análisis |
Referencias
Section titled “Referencias”- Apache Avro Documentation: https://avro.apache.org/
- Apache Parquet Format: https://parquet.apache.org/
- Apache ORC: https://orc.apache.org/
- PyArrow Documentation: https://arrow.apache.org/docs/python/
- Fastavro: https://github.com/fastavro/fastavro
- AWS Athena Pricing: https://aws.amazon.com/athena/pricing/
Ejercicios Prácticos
Section titled “Ejercicios Prácticos”Ejercicio 1: Airline Delay and Cancellation Data
Section titled “Ejercicio 1: Airline Delay and Cancellation Data”https://www.kaggle.com/datasets/yuanyuwendymu/airline-delay-and-cancellation-data-2009-2018
Mediante Python y utilizando Kaggle, crea un notebook a partir de los datos del dataset de retrasos en los vuelos y a partir de uno de los ficheros (el que más te guste), y teniendo en cuenta que los campos están separados por comas (,), transforma los datos y persiste los siguientes archivos:
- air
.parquet: el archivo CSV en formato Parquet. - air
.orc: el archivo CSV en formato ORC. - air
_snappy.orc: el archivo CSV comprimido en formato Snappy en formato ORC. - air
_small.avro: la fecha (FL_DATE), el identificador de la aerolínea (OP_CARRIER) y el retraso de cada vuelo (DEP_DELAY) en formato Avro. - air
_small.parquet: con los mismos atributos pero en Parquet. i
# TIP: Mediante Pandas, cuando tenemos un DataFrame, podemos seleccionar un subconjunto de las columnas de la siguiente forma:# df es un DataFrame que contiene todas las columnasdf_small = df[['FL_DATE', 'OP_CARRIER', 'DEP_DELAY']]# Para ver el tamaño de los archivosimport osos.path.getsize("/kaggle/working/air20XX.parquet)
# Para calcula el tiempo en realizar la conversiónimport time
inicio = time.time()# operación a medirfin = time.time()print(fin - inicio)Para poder realizar el ejercicio, es necesario crear una cuenta en Kaggle para que, al ejecutar el cuaderno, la instancia de la máquina pueda cargar tantos datos. Al estar registrado, de forma gratuita, las instancias permiten almacenar hasta 73 GB de datos y emplear 30GB de RAM durante 12 horas. Si no, sólo dispondremos de 1GB de RAM.

Una vez se abra el editor, ejecutamos el primer bloque de código y nos dará un listado de archivos con su ruta completa, debemos elegir uno de ellos para hacer los diferentes puntos del ejercicio.
/kaggle/input/airline-delay-and-cancellation-data-2009-2018/2011.csv/kaggle/input/airline-delay-and-cancellation-data-2009-2018/2013.csv/kaggle/input/airline-delay-and-cancellation-data-2009-2018/2015.csv/kaggle/input/airline-delay-and-cancellation-data-2009-2018/2014.csv/kaggle/input/airline-delay-and-cancellation-data-2009-2018/2009.csvEjercicio 2: Conversión de formatos
Section titled “Ejercicio 2: Conversión de formatos”Toma un archivo CSV y conviértelo a Avro, Parquet y ORC. Compara tamños y tiempos:
import pandas as pdimport timeimport osfrom fastavro import writer, parse_schemaimport pyarrow.parquet as pqimport pyarrow as pa
# Medir tiempo y tamañoresultados = {}
# CSV originaldf = pd.read_csv('datos.csv')tamaño_csv = os.path.getsize('datos.csv')print(f"CSV original: {tamaño_csv / (1024**2):.2f} MiB")
# Parquetinicio = time.time()df.to_parquet('datos.parquet')tiempo_parquet = time.time() - iniciotamaño_parquet = os.path.getsize('datos.parquet')print(f"Parquet: {tamaño_parquet / (1024**2):.2f} MiB en {tiempo_parquet:.2f}s")
# ORCinicio = time.time()df.to_orc('datos.orc')tiempo_orc = time.time() - iniciotamaño_orc = os.path.getsize('datos.orc')print(f"ORC: {tamaño_orc / (1024**2):.2f} MiB en {tiempo_orc:.2f}s")
# Resumenprint(f"\nCompresión vs CSV:")print(f" Parquet: {(1 - tamaño_parquet/tamaño_csv)*100:.1f}% reducción")print(f" ORC: {(1 - tamaño_orc/tamaño_csv)*100:.1f}% reducción")Ejercicio 3: Evolución de esquema en Avro
Section titled “Ejercicio 3: Evolución de esquema en Avro”Define un esquema v1, escribe datos, luego define v2 con un campo adicional:
# v1: Solo nombre y edadschema_v1 = { "type": "record", "name": "Persona", "fields": [ {"name": "nombre", "type": "string"}, {"name": "edad", "type": "int"} ]}
# v2: Añade emailschema_v2 = { "type": "record", "name": "Persona", "fields": [ {"name": "nombre", "type": "string"}, {"name": "edad", "type": "int"}, {"name": "email", "type": ["null", "string"], "default": None} ]}
# Escribe con v1, lee con v2# ✅ Avro lo permite# ⌠CSV requeriría reprocesar todo