Configurar cluster YARN
🚀 Presentación: YARN
Preparar contenedor
Section titled “Preparar contenedor”Para acceder al contenedor desde el exterior necesitamos “mapear” el puerto 8088. No se puede mapear un puerto en un contenedor que ya existe, por lo que debebos:
- Parar el contenedor.
- Crear una imagen basada en el contenedor.
- Crear un contenedor (basado en la imagen que hemos creado) con los puertos que necesitamos abiertos.
# Detenemos el contenedor de hadoopdocker stop hadoop
# Creamos una nueva imagen basada en este contenedordocker commit hadoop hadoopyarnsha256:c7cb29660093cf8d224cfa3411c8d2d7a1003b1574fdb2ed3a4d3079ff22fc04
# Iniciamos un nuevo contenedor con la nueva imagen# Puerto 8042 para acceder a un nodo en concreto# Puerto 8088 para acceder a la web que crea YARNdocker run -it -p 8042:8042 -p 8088:8088 -p 9870:9870 -p 9000:9000 --name hadoopyarncontainer --hostname hadoop hadoopyarnConfigurar cluster
Section titled “Configurar cluster”Paramos el cluster (user hadoop)
$ stop-dfs.shVamos a la carpeta donde se encuentran los ficheros de configuración
$ cd /opt/hadoop/etc/hadoop/Editamos para indicar que el motor que gestiona mapreduce será yarn:
$ vi mapred-site.xml
<configuration> <property> <name>yarn.app.mapreduce.am.env</name> <value>HADOOP_MAPRED_HOME=/opt/hadoop</value> </property> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property></configuration>Añadimos 3 propiedades a yarn-site.xml
- Indicamos donde se encuentra el yarn. Indicamos quién es el maestro que va a gestionar los procesos YARN.
- Servicios auxiliares que deben iniciar en el NodeManager (si por ejemplo creamos un servicio que se llame “myservice” lo podríamos indicar aquí).
- Cuál es la clase que va a utilizar para hacer esa gestión.
$ vi yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property></configuration>Arrancamos
# Primero la parte de datos$ start-dfs.sh
# Después la parte de procesos$ start-yarn.shComprobamos que todos los servicios están funcionando:
$ jps791 DataNode713 NameNode1294 NodeManager1214 ResourceManager927 SecondaryNameNode1647 JpsWeb admin YARN
Section titled “Web admin YARN”Se puede acceder a la web para ver la configuración del yarn a través del puerto 8088.
Nos aseguramos que esté el puerto abierto en la máquina virtual:
# Si no existe el comando netstat, debemos instalar el paquete net-tools
$ netstat -anp | grep 8088tcp 0 0 0.0.0.0:8088 0.0.0.0:* LISTEN 1214/javaOpciones Web admin YARN
Section titled “Opciones Web admin YARN”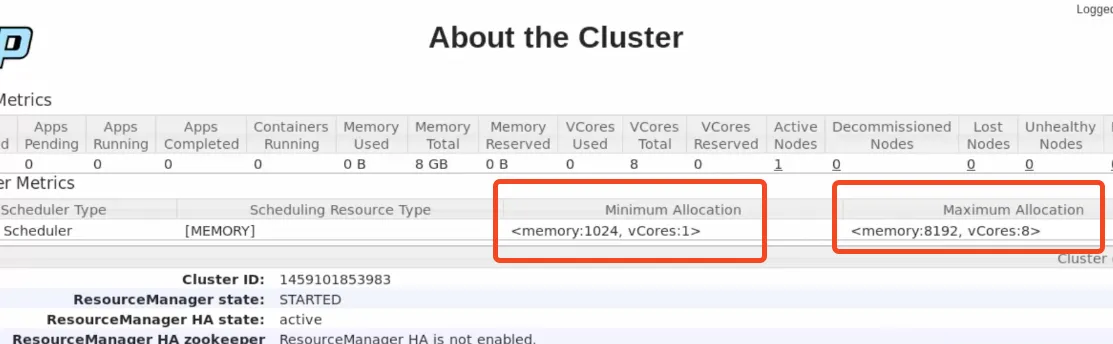 Por defecto asume que tendrá mínimo 1Gb y Máximo 8Gb (da igual cuanta memoria tenga nuestra máquina virtual)
Por defecto asume que tendrá mínimo 1Gb y Máximo 8Gb (da igual cuanta memoria tenga nuestra máquina virtual)
- Pestaña NODOS, nodos activos En nuestro caso habrá 1 nodo activo y nos podemos comunicar con él por el puerto 8042 Si pinchamos en el nodo podremos ver sus propiedades, aplicaciones que está lanzando, contenedores (recursos reales que se utilizan para hacer los procesos).
- Node Labels (para etiquetar los diferentes nodos, no lo vamos a utilizar.
- Applications: Las aplicaciones que tenemos funcionando en este momento. (Se pueden seleccionar por estado, NEW, NEW SAVING, SUBMITTED, ACCEPTED…)
- Schenduler: Métricas del planificador, podemos ver lo que ha ocurrido cuando lancemos una aplicación. Por el momento aparecerá vacío.
- Tools: Podemos ver la configuración, logs, estadísticas….
Prueba MapReduce
Section titled “Prueba MapReduce”Vamos a probar MapReduce con los ejemplos que ya ejecutamos en el punto anterior.
En primer lugar, contaremos las veces que aparece la cadena “kms” en los archivos de configuración de hadoop, pero esta vez a través de HDFS.
- Creamos una carpeta en hdfs llamada /tmp/entrada
- Copiamos los xml de /opt/hadoop/etc/hadoop/ dentro de la carpeta
$ cd /opt/hadoop/share/hadoop/mapreduce/
# Antes de ejecutar cargamos la URL donde se pueden ver los jobs de YARN$ hadoop jar hadoop-mapreduce-examples-3.3.6.jar grep /tmp/entrada /tmp/salida/ 'kms'Si accedemos a la URL de yarn veremos información del trabajo que ha realizado.
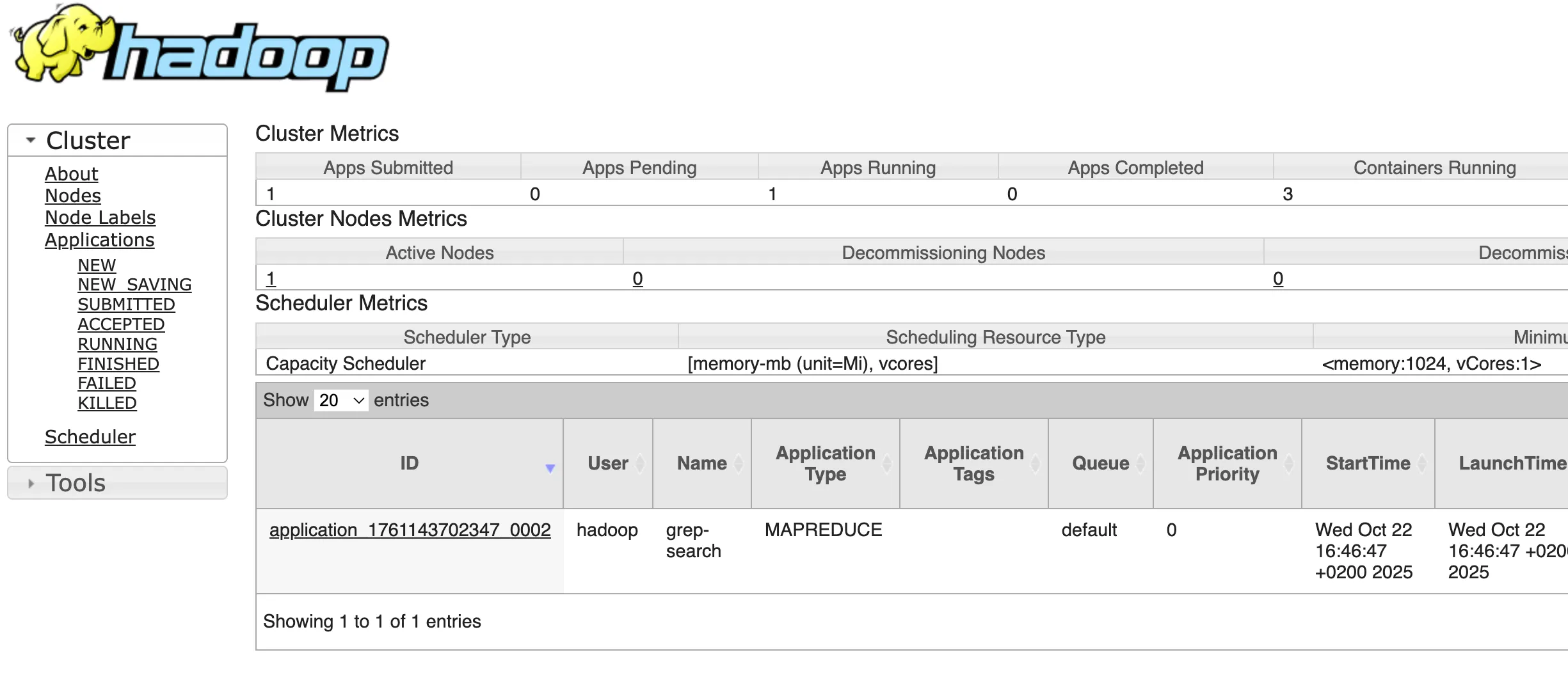
Posibles errores
Section titled “Posibles errores”ERROR, hadoop3
Para los que uséis la versión 3 de Hadoop, a veces puede generar un error al realizar alguno de los ejemplos.
Para solucionarlo, es necesario explicitar algunas librerías
En concreto hay que añadir en el yarn-site.xml la siguiente entrada (por supuesto adaptarlo a vuestro HADOOP_HOME.
<property> <name>yarn.application.classpath</name> <value> /opt/hadoop3/hadoop/etc/hadoop, /opt/hadoop3/share/hadoop/common/*, /opt/hadoop3/share/hadoop/common/lib/*, /opt/hadoop3/share/hadoop/hdfs/*, /opt/hadoop3/share/hadoop/hdfs/lib/*, /opt/hadoop3/share/hadoop/mapreduce/*, /opt/hadoop3/share/hadoop/mapreduce/lib/*, /opt/hadoop3/share/hadoop/yarn/*, /opt/hadoop3/share/hadoop/yarn/lib/* </value></property>ERROR, no se puede acceder a yarn
Si no se puede acceder: https://github.com/apache/samza-hello-samza/pull/1
Al configurar todo en el mismo cluster hay un problema con la propiedad que hemos añadido en yarn-site.xml indicando el hostname. Por lo que:
- Borramos esta propiedad.
- Paramos yarn.
- Volvemos a arrancar yarn.
$ netstat -anp | grep 8088 tcp 0 0 0.0.0.0:8088 0.0.0.0:* LISTEN 2144/javaYa debería ser accesible.