Comandos y operaciones básicas en HDFS
🚀 Presentación: HDFS
Opciones básicas
Section titled “Opciones básicas”Hay que asegurarse que está arrancado HDFS
El comando hdfs se encuentra de la carpeta /opt/hadoop/biny el sistema busca en esta carpeta porque la habíamos incluido en nuestro $PATH.
Mostramos todas las opciones posibles del comando hdfs dfs.
El comando hdfs “emula” comandos Linux como verás posteriormente.
$ echo $PATH$ hdfs dfs #Muestra todos los comandos posibles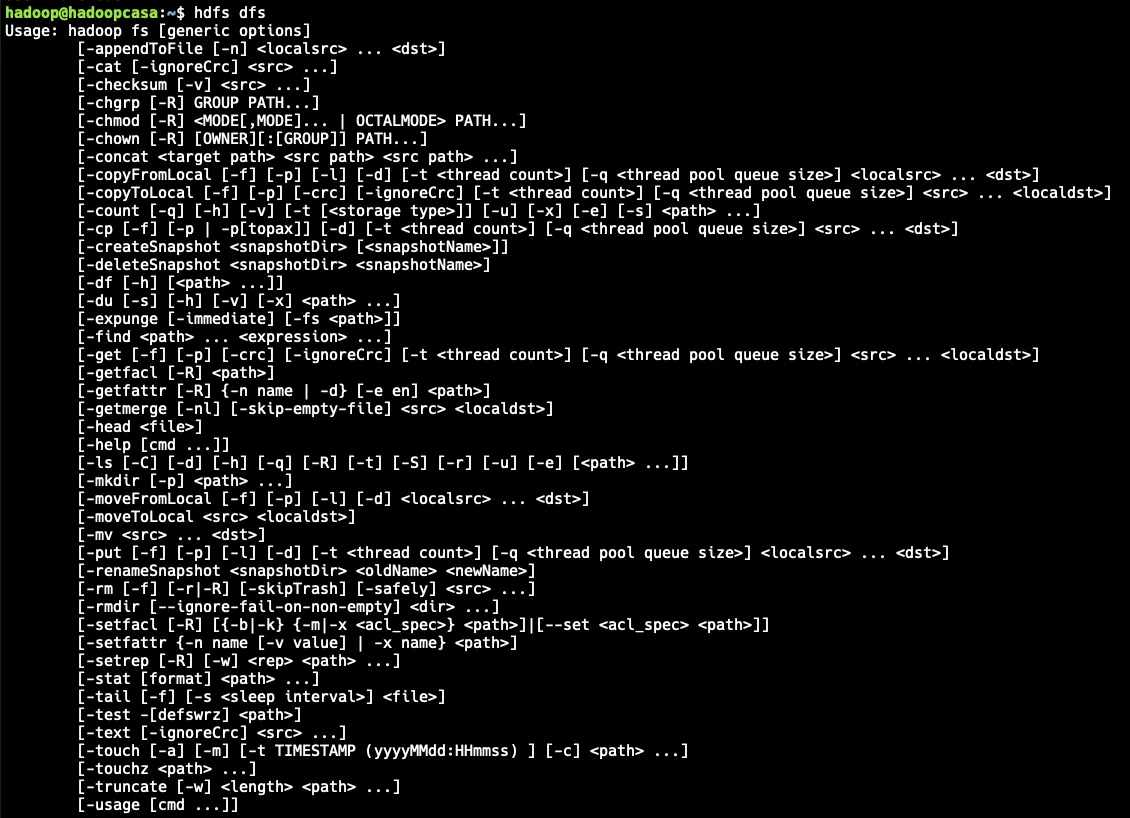
Para visualizar el contenido actual del sistema de ficheros HDFS.
$ hdfs dfs -ls /EJERCICIO 1
- Crear un fichero simple en local (prueba.txt).
- Crear un directorio en el sistema de ficheros DFS (/temporal)
- Copiar el archivo que hemos creado al directorio remoto.
Desde el explorador la web de administración, podemos ver información del archivo y bloques.
Nos fijamos en Bloock ID y Bloock Pool
¿Cómo hacerlo a través de un comando?
$ hdfs fsck /temporal/prueba.txt -files -blocks
Connecting to namenode via http://debianh:9870/fsck?ugi=hadoop&files=1&blocks=1&path=%2Fhola.txt FSCK started by hadoop (auth:SIMPLE) from /127.0.0.1 for path /hola.txt at Mon Nov 06 14:08:52 CET 2023
/temporal/prueba.txt 5 bytes, replicated: replication=1, 1 block(s): OK 0. **BP-673766993-127.0.1.1-1698337131957**:blk_**1073741825**_1001 len=5 Live_repl=1Ahora vamos a comprobar cómo HDFS ha guardado el archivo en local. Para ello vamos a:
$ cd /datos/datanode/currentEncontraremos una carpeta con el mismo nombre que el Bloock Pool, en mi caso entraré con:
cd BP-673766993-127.0.1.1-1698337131957# Accedemos a sus subdirectorioscd current/finalized/subdir0/subdir0/En este momento podremos ver el bloque que debe encajar con el Block ID
$ lsblk_1073741825
$ cat blk_1073741825holaPodemos borrar todo recursivamente con:
hdfs dfs -rm -r /temporalEjercicios ✏️
Section titled “Ejercicios ✏️”Podéis encontrar los archivos de datos en el siguiente repositorio: https://github.com/josepgarcia/datos
Ejercicio 1. Fichero de logs.
Section titled “Ejercicio 1. Fichero de logs.”- Descargamos un fichero más grande (access_log.gz )
- Lo descomprimimos. Quedará un archivo de 482mb.
- Lo movemos a HDFS, dentro la carpeta
- Comprobamos en cuantos bloques se encuentra.
- ¿A qué archivos apunta en el contendor?
Ejercicio 2
Section titled “Ejercicio 2”- Crea un fichero
saludo.txten local, que contenga el texto “Hola”. Súbelo a HDFS, a la carpeta /temporal (si no existe hay que crearla) Borra el fichero en local Muestra el contenido del fichero (en remoto). - Copia el fichero saludo.txt a local con el nombre (saludolocal.txt)
- Entra a la web de administración para ver que existe el fichero.
- Borra el fichero remoto.
- Asegúrate que se ha borrado el fichero con ls.
- Borra el directorio temporal.
Ejercicio 3
Section titled “Ejercicio 3”- Crea un fichero “otrosaludo.txt” en local, que contenga el texto “Hola”. MUÉVELO a HDFS, dentro de la carpeta /ejercicios/saludos/ Comprueba que ya no existe el fichero en local
- Crea un directorio en local llamado prueba Dentro de este directorio crea un fichero llamado ejercicioprueba.txt Mueve todo el directorio prueba a HDFS, dentro de la carpeta /ejercicios Comprueba que ya no existe la carpeta en local Realiza una copia de HDFS a local de la carpeta que acabas de subir.
Ejercicio 4
Section titled “Ejercicio 4”-
Crea un archivo en /tmp llamado archivogrande que tenga un tamaño de 500MB (aproximadamente)
TIP: Utiliza el comando dd para crear el fichero -
Crea una carpeta en HDFS llamada datos2.
-
Sube el archivo a la carpeta creada.
Administración
Section titled “Administración”Con la herramienta dfsadmin podemos examinar el estado del cluster HDFS.
$ hdfs dfsadmin
# Ejemplo:$ hdfs dfsadmin -safemode enterOpciones dfsadmin
- hdfs dfsadmin -report: Resumen completo del sistema HDFS; estado de todos los nodos del clúster, su capacidad, el espacio utilizado…
- hdfs fsck: Comprobar la integridad del sistema de archivos HDFS. Para verificar un directorio hay que añadirlo como segundo parámetro.
hdfs fsck /datos/prueba - hdfs dfsadmin -printTopology: Este comando revela la topología del clúster HDFS. Proporciona información sobre la distribución de nodos y muestra a qué rack pertenece cada nodo.
- hdfs dfsadmin -listOpenFiles: Una tarea crítica en la administración de HDFS es garantizar que no haya archivos abiertos que puedan causar problemas en el sistema. Este comando lista todos los archivos abiertos en el clúster, lo que facilita la identificación y solución de problemas.
- hdfs dfsadmin -safemode enter: El modo seguro de HDFS es una característica importante para prevenir modificaciones accidentales en el sistema de archivos. Al ingresar al modo seguro, se evita la escritura y modificación de datos en el clúster. Esto puede ser útil durante operaciones de mantenimiento o actualizaciones críticas.
- hdfs dfsadmin -safemode leave: Cuando se completa la operación en modo seguro y se requiere que el sistema vuelva a estar en pleno funcionamiento, se puede salir del modo seguro con este comando.
Ejercicios ✏️
Section titled “Ejercicios ✏️”- Muestra un resumen de recursos.
- Comprueba el estado del sistema de ficheros.
- Comprueba el estado del directorio datos2.
- Muestra la topología actual. Hadoop es consciente de los racks que tiene la máquina (se lo decimos nosotros), así organiza mejor los bloques (los replica en racks distintos)
- ¿Hay algún fichero abierto?
$ hdfs dfsadmin -report "Under replicated blocks" -> Si configuramos como réplica por ejemplo 3 y hay algún bloque con menos. Si esto baja de un determinado porcentaje, hadoop se pone en modo seguro porque piensa que hay algún problema.$ hdfs fsck /$ hdfs fsck /datos2$ hdfs dfsadmin -printTopology$ hdfs dfsadmin -listOpenFilesSnapshots
Section titled “Snapshots”- https://labex.io/tutorials/hadoop-how-to-restore-a-directory-from-a-snapshot-in-hadoop-hdfs-414945
- https://labex.io/tutorials/hadoop-how-to-check-contents-of-a-restored-snapshot-in-hadoop-hdfs-414942
En esta práctica vamos a realizar un snapshot y utilizarlo para recuperar un fichero que hemos borrado accidentalmente.
Pasos a seguir:
- Creamos un directorio llamado
datosdentro de DFS - Subimos a ese directorio un fichero llamado
f1.txtque contenga “Esto es una prueba”.
Ahora vamos a ver dónde ha dejado este fichero:
- ¿Cómo se localiza el fichero desde webdfs?
- ¿Cómo se localiza el fichero desde la línea de comandos?
 Solución
Solución
$ hdfs fsc /datos/f1.txt -blocks -locations -files
Realizar el snapshot
Section titled “Realizar el snapshot”- Activamos para que se puedan hacer snapshots y realizamos uno
hdfs dfsadmin -allowSnapshot /datos
hdfs dfs -createSnapshot /datos snap1## La creación del snapshot no se hace con dfsadmin sino con dfs
hdfs dfs -ls /datos/.snapshot/snap1## Nos muestra el fichero tal y como estaba cuando hicimos el snap- ¿El snapshot aparece en webdfs? Compruébalo
Borrar y recuperar fichero
Section titled “Borrar y recuperar fichero”Una vez tenemos la copia realizada borramos el fichero f1.txt en HDFS
hdfs dfs -rm /datos/f1.txtLo podemos recuperar desde el snapshot con:
hadoop fs -cp /datos/.snapshot/snap1/f1.txt /datos/## -cp solo hace copias entre HDFS, para "sacar" el fichero de HDFS hay que utilizar -get
hdfs dfs -ls /datosBorrar snapshot
Section titled “Borrar snapshot”hdfs dfs -deleteSnapshot /datos snap1Desactivar snapshots
Section titled “Desactivar snapshots”hdfs dfsadmin -disallowSnapshot /datoshttps://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsSnapshots.html
Acceso desde python
Section titled “Acceso desde python”En la misma máquina donde tenemos instalado hadoop:
- Creamos un entorno virtual.
- Instalamos los paquetes:
- hdfs
- pandas
- Ejecutamos el siguiente script.
import pandas as pdfrom hdfs import InsecureClient
client = InsecureClient('http://localhost:9870')with client.read('/productos.csv') as file: df = pd.read_csv(file)
print(df.head())print(df.info())print(df.describe().transpose())print(client.list('/'))# Bajando un archivo de Hadoop a nuestro localclient.download('/productos.csv', './productos.csv')# Bajando multiples archivos#for file in client.list('/'):# client.download(f'/{file}', './csv')client.upload('/','test.py')print(client.list('/'))client.delete('/test.py')Posibles errores
Section titled “Posibles errores”ERROR1
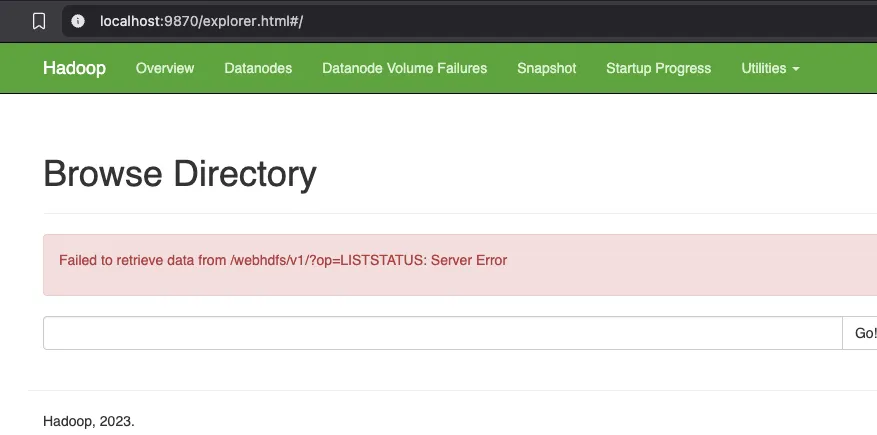 Si accedemos a la url que indica la consola de desarrolladores vemos el error:
http://localhost:9870/webhdfs/v1/?op=LISTSTATUS
Si accedemos a la url que indica la consola de desarrolladores vemos el error:
http://localhost:9870/webhdfs/v1/?op=LISTSTATUS
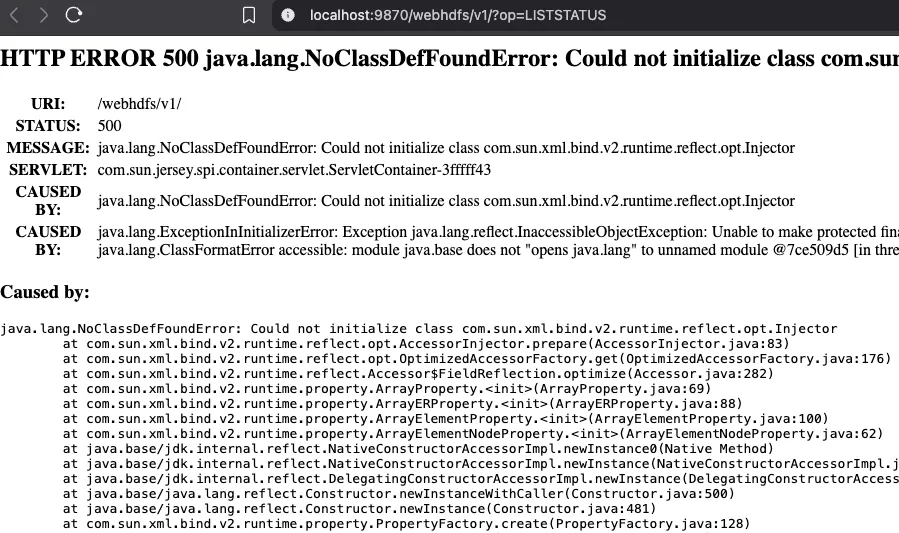 Este error se debe a que tenemos instalada la versión 17 de openjdk y hadoop es compatible hasta la versión 11.
Para solucionarlo, debemos descargar en
Este error se debe a que tenemos instalada la versión 17 de openjdk y hadoop es compatible hasta la versión 11.
Para solucionarlo, debemos descargar en /opt la versión 11 de java e indicarle al sistema que la utilice:
https://learn.microsoft.com/en-us/java/openjdk/download#openjdk-11
- La descargamos en
/opt - La descomprimimos y creamos un enlace a la misma llamado
jdk11 - Actualizamos el gestor de versiones de ubuntu con la nueva versión de java (como root) y la seleccionamos:
- `update-alternatives —install /usr/bin/java java /opt/jdk11/bin/java 11’
- update-alternatives —config java
- Al ejecutar
java -versionya tendremos la versión 11 por defecto en el sistema. - Ahora debemos de:
- Detener dfs
- Actualizar el .bashrc del usuario hadoop con la nueva versión de Java
- Actualizar también la ruta de java en los ficheros de configuración de hadoop.
- Si hemos hecho todo lo necesario, ya no saldrá el error:
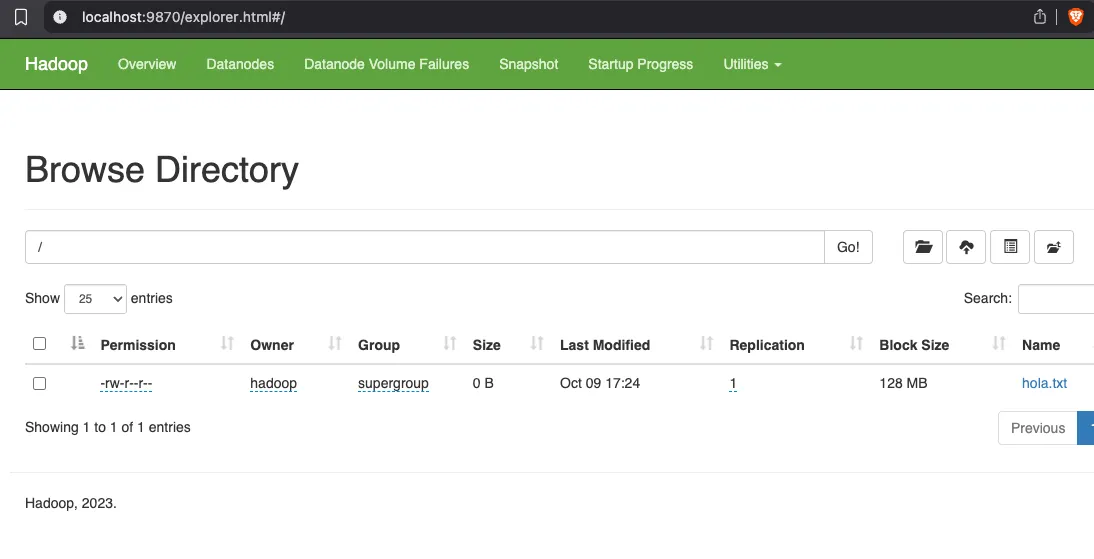
ERROR2
No aparece información del archivo
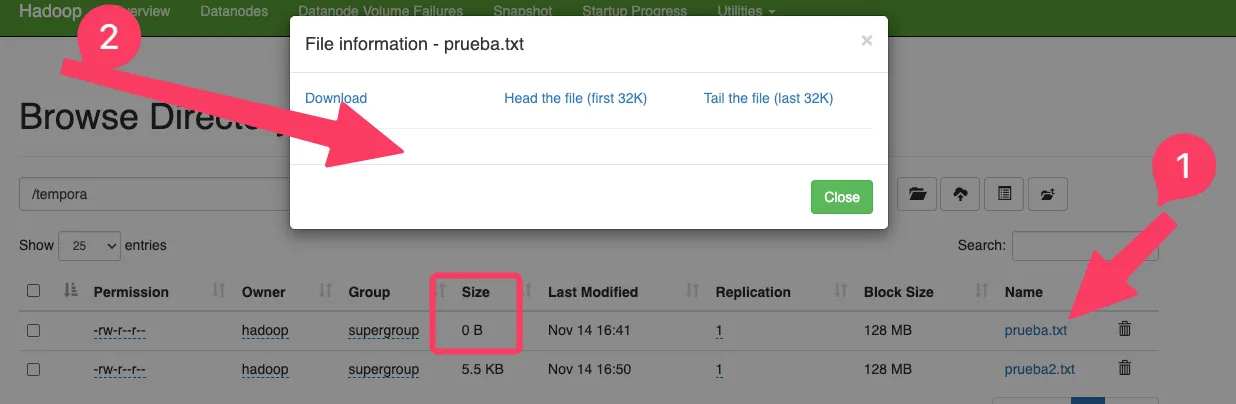 Se trata de un archivo vacío.
Se trata de un archivo vacío.
ERROR3

Este error se debe a que no tenemos expuesto (abierto) el puerto 9864en nuestro contenedor.