Configuración de un Cluster Hadoop Pseudodistribuido
Requisitos
Section titled “Requisitos”- Hadoop descargado y descomprimido en /opt (lo hicimos anteriormente).
- El usuario hadoop ha de poder conectarse como usuario hadoop sin password (Tutorial ssh)
- El usuario
hadoopha de poder realizar unssh hadoop@localhosty ha de loguearse automáticamente, sin que se le pida password.
- El usuario
Configuración del cluster
Section titled “Configuración del cluster”- Iniciamos el contenedor y accedemos a él.
- Nos logueamos como
hadoop
docker start hadoopdocker exec -it hadoop bash# Nos logueamos como hadoop$ su - hadoop
# Debemos poder acceder por ssh a localhost sin contraseña$ ssh localhost
# Accedemos a la carpeta de configuración hadoop$ cd /opt/hadoop/etc/hadoop/
$ lscapacity-scheduler.xml hadoop-user-functions.sh.example kms-log4j.properties ssl-client.xml.exampleconfiguration.xsl hdfs-rbf-site.xml kms-site.xml ssl-server.xml.examplecontainer-executor.cfg **hdfs-site.xml** log4j.properties user_ec_policies.xml.template**core-site.xml** httpfs-env.sh mapred-env.cmd workershadoop-env.cmd httpfs-log4j.properties mapred-env.sh yarn-env.cmdhadoop-env.sh httpfs-site.xml mapred-queues.xml.template yarn-env.shhadoop-metrics2.properties kms-acls.xml **mapred-site.xml** yarnservice-log4j.propertieshadoop-policy.xml kms-env.sh shellprofile.d **yarn-site.xml**Ficheros más importantes.
core-site.xml → configuración general del cluster.hdfs-site.xml → configuración sistema de ficheros hdfs.mapred-site.xml → configuración de mapreduce. # de moment nohadoop-env.sh -> entorno del servidoryarn-site.xml → configuración del modo de trabajo del proceso yarn. # de moment noEmpezamos con la configuración del servidor hadoop.
core-site.xml
Section titled “core-site.xml”Inicialmente está vacío.
Lo modificamos para indicarle:
- name: Qué sistema de fichero vamos a utilizar en hadoop (por defecto hdfs, hay otros).
- value: Dónde se encuentra el servidor maestro que va a contener los datos (Namenode) estará en nodo1 (la máquina donde me encuentro, puerto 9000)
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property></configuration>hdfs-site.xml
Section titled “hdfs-site.xml”dfs.replication→ Por defecto cada bloque se replica 3 veces, como tenemos 1 nodo, indicamos que solo hay 1 nodo que no replique.dfs.namenode.name.dir→ Dónde se encuentra la información del maestro (los metadatos que guarda el maestro). Solo se indica en los clusters “maestro”, pero como estamos haciendo un cluster pseudodistribuido lo indicamos.dfs.datanode.data.dir→ En cada esclavo dónde se guardan los datos. Solo se indica en los clusters “esclavos”, pero como estamos haciendo un cluster pseudodistribuido lo indicamos.
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/datos/namenode<value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/datos/datanode</value> </property></configuration>hadoop-env.sh
Section titled “hadoop-env.sh”Añadimos la variable JAVA_HOME con la ruta donde se encuentra nuestra instalación.
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-arm64Directorios y sistema de ficheros
Section titled “Directorios y sistema de ficheros”Como usuario root
- Creamos los directorios configurados en el punto anterior
/datos/namenode/datos/datanode- Cambiamos el propietario y grupo de /datos a
hadoop.
$ ls -la /datostotal 16drwxr-xr-x 4 hadoop hadoop 4096 oct 26 08:28 .drwxr-xr-x 19 root root 4096 oct 26 08:28 ..drwxr-xr-x 2 hadoop hadoop 4096 oct 26 08:28 datanodedrwxr-xr-x 2 hadoop hadoop 4096 oct 26 08:28 namenodeComo usuario hadoop
- Creamos el sistema de ficheros del namenode (lo creará donde le hemos indicado en el xml).
# Formateamos el namenode$ hdfs namenode -format
# Podemos de ver lo que ha creado...$ ls /datos/namenode/*Arrancamos HDFS
Section titled “Arrancamos HDFS”Vamos a iniciar el servidor HDFS, deben arrancar namenode, secondary namenode y datanode.
En este momento vamos a iniciar ya el servidor de hadoop, quedará en memoria hasta que lo detengamos.
Vamos a la carpeta sbin dentro de hadoop.
$ cd /opt/hadoop/sbin/$ start-dfs.sh# 1. Arranca namenode# 2. Arranca datanode# 3. Arranca secondarynamenodePara detener el cluster lo haremos con:
$ stop-dfs.shDentro de las JDK de java, tenemos un comando para ver los procesos java en ejecución:
$ jps3218 DataNode3143 NameNode3592 Jps3485 SecondaryNameNode
# También podemos utilizar$ ps -fe | grep javaComprobamos las carpetas de datos
$ ls /datos/namenode/current in_use.lock
# Ahora esta carpeta ya tiene datos$ ls -a /datos/datanode/. .. current in_use.lockPara acceder a la administración HDFS via web se utilizan 2 puertos:
- 9870 -> Hadoop 3, versión actual.
- 9000 -> HDFS
Ya podemos acceder a la web de administración:
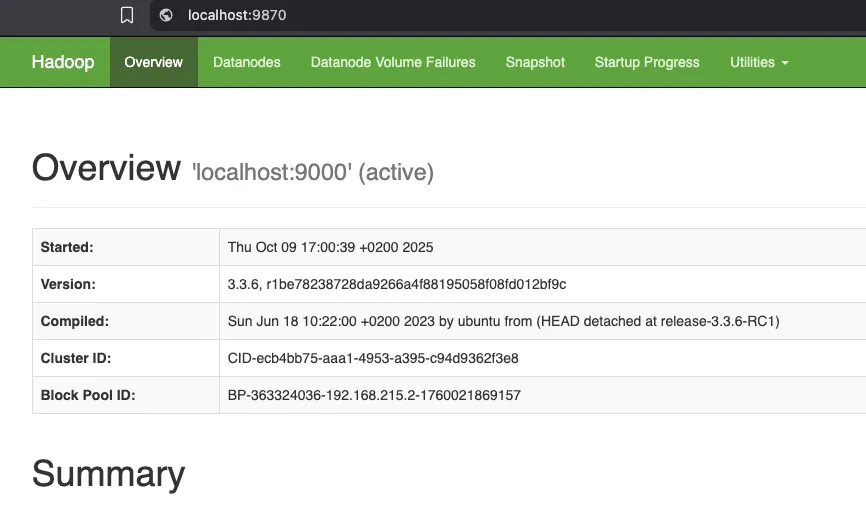
Una vez en la web de administración, pestaña DATANODES podemos acceder a un determinado nodo, en nuestro caso al ser un cluster pseudodistribuido solamente tenemos un nodo.

Pendiente, acceso al nodo a través del puerto 9864 http://localhost:9864/ → Menos opciones ya que accedemos a un nodo determinado
Trabajar con HFS
Section titled “Trabajar con HFS”En /datos/namenode/current hay 3 tipos de ficheros:
-rw-r--r-- 1 hadoop hadoop 42 oct 26 09:09 edits_0000000000000000001-0000000000000000002-rw-r--r-- 1 hadoop hadoop 42 oct 26 10:09 edits_0000000000000000003-0000000000000000004-rw-r--r-- 1 hadoop hadoop 42 oct 26 12:34 edits_0000000000000000005-0000000000000000006-rw-r--r-- 1 hadoop hadoop 1048576 oct 26 12:34 edits_inprogress_0000000000000000007-rw-r--r-- 1 hadoop hadoop 401 oct 26 10:09 fsimage_0000000000000000004-rw-r--r-- 1 hadoop hadoop 62 oct 26 10:09 fsimage_0000000000000000004.md5-rw-r--r-- 1 hadoop hadoop 401 oct 26 12:34 fsimage_0000000000000000006-rw-r--r-- 1 hadoop hadoop 62 oct 26 12:34 fsimage_0000000000000000006.md5-rw-r--r-- 1 hadoop hadoop 2 oct 26 12:34 seen_txid-rw-r--r-- 1 hadoop hadoop 214 oct 26 08:35 VERSION$ cat VERSION#Thu Oct 26 08:35:28 CEST 2023namespaceID=623528578blockpoolID=BP-1493409649-127.0.1.1-1698302128453storageType=NAME_NODEcTime=1698302128453clusterID=CID-ca9bde81-b05d-4fcc-8c4c-b54887eada3blayoutVersion=-66Si paramos el cluster con stop-dfs.sh y lo volvemos a arrancar los números en los nombres de ficheros incrementan.
-
edits_: cambios dentro de la base de datos de HDFS.
-
editsinprogress: lo que se está escribiendo en este momento.
-
fsimage_: copia “foto”, de un momento en el tiempo del sistema de ficheros.
-
Fichero VERSION
-
namespaceID: identificador único para el sistema de archivos HDFS en un clúster. Este identificador se utiliza para distinguir entre diferentes instancias del sistema de archivos HDFS en clústeres distintos. Cada clúster de Hadoop debe tener unnamespaceIDúnico para evitar conflictos. Si clonas o replica un clúster Hadoop, es importante que elnamespaceIDsea diferente en cada clúster para que no haya confusiones. -
blockpoolID: identificador único para el “block pool” en HDFS. El “block pool” es una colección de bloques de datos que se utilizan para almacenar los datos de los archivos en HDFS. Cada “block pool” tiene su propioblockpoolID, que se utiliza para diferenciar entre múltiples “block pools” en el mismo clúster. Esto es importante para la escalabilidad y la administración de bloques en el sistema de archivos. -
clusterID: identificador único para el clúster Hadoop. Este valor se utiliza para identificar un clúster específico y es importante para asegurarse de que los nodos del clúster se estén conectando al clúster correcto. ElclusterIDes necesario para garantizar que no haya problemas de conexión entre nodos cuando hay varios clústeres en la misma red o en escenarios de recuperación de desastres.
-
Posibles errores
Section titled “Posibles errores”ERROR1 en el sistema de ficheros HDFS, podemos utilizar fsck
En el log de datanode: $ tail -f logs/hadoop-hadoop-datanode-debianh.log
2023-10-26 18:24:38,407 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool (Datanode Uuid 6dfbb007-34b1-4a07-a045-274aad0e2936) service to debianh/127.0.1.1:9000. Exiting.
$ hdfs fsck / -includeSnapshots# Borramos la carpeta current del namenode$ rm -rf /datos/datanode/current
# Iniciamos datenode unicamente$ hdfs --daemon start datanode
$ jps2688 NameNode3486 DataNode3582 Jps
# Cuando ya no caiga DataNode$ start-all.shERROR2: Eliminar los warnings que aparecen al iniciar dfs
Error: WARN util.NativeCodeLoader No encuentra librerías nativas, no importa, es un warning (podría ir más lento debido a este error) Para eliminar el warning hay que añadir en .bashrc
export HADOOP_HOME_WARN_SUPRESS=1export HADOOP_ROOT_LOGGER="WARN,DRFA"ERROR 3 ssh
Si no configuraste el ssh sin contraseña, devolverá el siguiente error, debemos configurarlo para que se levanten los servicios.
./start-dfs.shStarting namenodes on [localhost]localhost: ssh: connect to host localhost port 22: Connection refusedStarting datanodeslocalhost: ssh: connect to host localhost port 22: Connection refusedStarting secondary namenodes [hadoop]hadoop: ssh: connect to host hadoop port 22: Connection refused2025-10-09 12:02:33,674 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable