Hadoop Standalone en contenedor Debian
🚀 Presentación: HADOOP
¿Qué es Hadoop Standalone?
Section titled “¿Qué es Hadoop Standalone?”Hadoop Standalone, también conocido como modo local o modo embebido, es la forma más básica de ejecutar Hadoop. En este modo:
- Todas las operaciones de MapReduce se ejecutan dentro de un único proceso de Java Virtual Machine (JVM) en tu máquina local.
- No se inician ni se comunican daemons como NameNode, DataNode, ResourceManager o NodeManager.
- El sistema de archivos utilizado es el local del sistema operativo (por ejemplo, ext4 o NTFS), en lugar de HDFS.
- No existe replicación de datos ni tolerancia a fallos: si tu disco local falla, pierdes los datos.
Información y descarga
Section titled “Información y descarga”
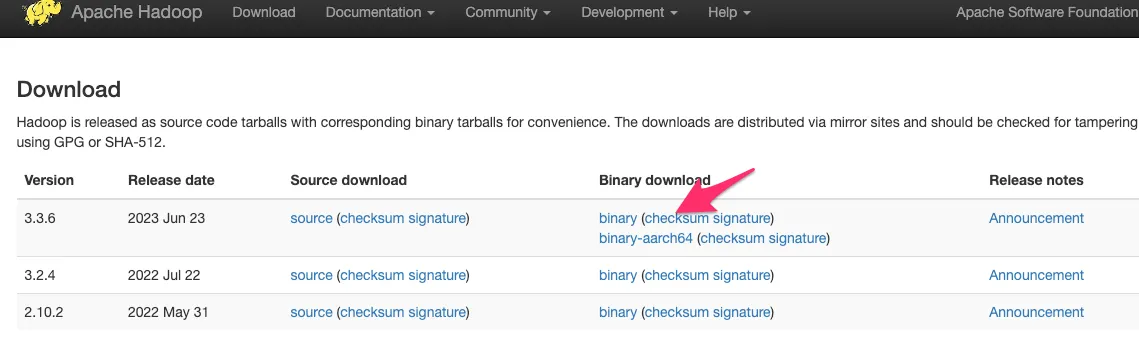 Vamos a utilizar la versión 3.3.6, nos quedamos con la URL des descarga del tar.gz
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
Vamos a utilizar la versión 3.3.6, nos quedamos con la URL des descarga del tar.gz
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
Tutorial de ejemplo, instalación en Ubuntu
Creación del contenedor
Section titled “Creación del contenedor”Vamos a crear un contenedor basado en debian 12 y a instalar Java y otras herramientas. En este contenedor vamos a utilizar dos puertos que deben ser accesibles desde el exterior, por lo que debemos mapearlos. Si creamos un contenedor sin mapear los puertos después no podemos hacerlo de una manera sencilla.
@todo: Montar un volumen o activar ssh para pasar de manera sencilla hadoop.tar.gz
# Puerto 9870 -> webdfs# Puerto 9000 -> hdfsdocker run -it --name hadoop -p 9870:9870 \ -p 9000:9000 --hostname hadoop debian:12 bash
# Dentro del contenedorapt update -y && \apt upgrade -y && \apt install -y openssh-server wget sudo vim nano net-tools curl@todo: Si no podemos abrir el puerto 9000, mapearlo
Recordemos el uso del comando apt
# Actualizar índice de paquetes (para ver si hay nuevas versiones)sudo apt update# Instalar un paquete o programasudo apt install [package_name]# Borrar un paqueteapt remove [package_name]# Borrar un paquete y ficheros de configuraciónapt purge [package_name]# Actualizar paquetes a la última versiónapt upgrade# Búsqueda de paquetesapt search [text_to_search]# "Arreglar" paquetes rotosapt -f installMás info en:
https://www.2daygeek.com/debian-ubuntu-apt-command-guide/
Instalamos java (OpenJDK)
apt install -y openjdk-17-jdk
# Ejecutamos y nos quedamos con el pathupdate-alternatives --config java# En mi caso: /usr/lib/jvm/java-17-openjdk-arm64/bin/java# Tu path será diferente, mi procesador es arm64, por ejemplo:# /usr/lib/jvm/java-17-openjdk-amd64/bin/javaVariable $PATH
Section titled “Variable $PATH”Descargamos hadoop
Section titled “Descargamos hadoop”El siguiente paso será descargar y descomprimir hadoop, para ello utilizaremos la carpeta /opt (que es una abreviatura de “optional”) es proporcionar una ubicación estandarizada y separada para instalar paquetes grandes y complejos, o suites de software, de manera que:
- No interfieran con los archivos del sistema operativo que se encuentran en carpetas como
/usr,/bin,/lib, etc. - El software se mantenga auto-contenido y fácilmente desinstalable, ya que sus archivos binarios, librerías, documentación, y archivos de configuración a menudo residen completamente bajo el subdirectorio de la aplicación en
/opt.
cd /optwget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gztar -zxvf hadoop-3.3.6.tar.gz
# Creamos un enlace simbólicoln -s hadoop-3.3.6 hadoopls -laConfiguración usuario para hadoop
Section titled “Configuración usuario para hadoop”Creamos un usuario hadoop y configuramos su entorno (path Java)
adduser hadoopchown -R hadoop:hadoop /opt/hadoop-3.3.6 /opt/hadoopls -la
su - hadoopEdita el archivo ~/.bashrc y añade al final, ten en cuenta que tu JAVA_HOME será otro
# JAVA y Hadoopexport JAVA_HOME=/usr/lib/jvm/java-17-openjdk-arm64export HADOOP_HOME=/opt/hadoopexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinRecargamos el archivo:
source ~/.bashrc
# Si todo ha ido bien, devolverá un resultado:$ java -versionopenjdk version "17.0.16" 2025-07-15OpenJDK Runtime Environment (build 17.0.16+8-Debian-1deb12u1)OpenJDK 64-Bit Server VM (build 17.0.16+8-Debian-1deb12u1, mixed mode, sharing)
$ echo $PATH/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games:/opt/hadoop/bin:/opt/hadoop/sbin
$ echo $HADOOP_HOME/opt/hadoopEn este momento ya podremos ejecutar hadoop desde cualquier directorio:
$ hadoop versionHadoop 3.3.6Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9cCompiled by ubuntu on 2023-06-18T08:22ZCompiled on platform linux-x86_64Compiled with protoc 3.7.1From source with checksum 5652179ad55f76cb287d9c633bb53bbdThis command was run using /opt/hadoop-3.3.6/share/hadoop/common/hadoop-common-3.3.6.jar
$ hadoop -hDirectorios dentro de Hadoop
Section titled “Directorios dentro de Hadoop”/opt/hadoop/bin -> "ejecutables" hadoop, hdfs, mapred, yar
/opt/hadoop/etc -> ficheros de configuracion xml
/opt/hadoop/lib -> librerías nativas
/opt/hadoop/sbin -> scripts, utilidades que me permiten entre otras cosas arrancar y parar hadoop
/opt/hadoop/share -> paquetes, ejemplos ...Comprobar el funcionamiento
Section titled “Comprobar el funcionamiento”Para comprobar que mapreduce funciona, vamos a ejecutar unos ejemplos que podemos encontrar dentro de share.
$ cd /opt/hadoop/share/hadoop/mapreduce
# Podemos ver los ejemplos que se pueden ejecutar ejecutando sobre el paquete de ejemplos mapreduce$ jar tf hadoop-mapreduce-examples-3.3.6.jar# Nos sale un listado de todos los comandos u opciones de este paquete
#### Vamos a ejecutar por ejemplo:#### org/apache/hadoop/examples/Grep.class
# Preparamos los directorios donde estarán los datos de entrada (en /tmp) y copiamos datos de entrada "demo",# por ejemplo ficheros de configuración de hadoop$ mkdir /tmp/entrada$ cd /tmp/entrada$ cp /opt/hadoop/etc/hadoop/*.xml .
## Vamos a buscar (tal y como hace grep), las palabras que contengan un determiando texto, en este caso## palabras que contengan el texto kms$ cd /opt/hadoop/share/hadoop/mapreduce/
## Invocamos al paquete de ejemplos, comando grep$ hadoop jar hadoop-mapreduce-examples-3.3.6.jar grep /tmp/entrada /tmp/salida/ 'kms'
## Hace una serie de procesos mapper y reducer (lo veremos más adelante)$ cd /tmp/salida/$ lspart-r-00000 _SUCCESS
# _SUCCESS -> ha sido satisfactorio
# ¿Cuántas veces ha encontrado la palabra kms?$ cat part-r-000009 kms
-------------------------------------------------# Se trata de un programa básico inicial para comprobar que funciona, podemos hacer lo mismo desde bash:cd /tmp/entradaegrep kms * | wc -lEjemplos de mapreduce
Section titled “Ejemplos de mapreduce”El fichero de ejemplos hadoop-mapreduce-examples, contiene los siguientes:
| Comando | Descripción |
|---|---|
| aggregatewordcount | Cuenta las palabras de los archivos de entrada. |
| aggregatewordhist | Calcula el histograma de las palabras de los archivos de entrada. |
| bbp | Usa una fórmula Bailey-Borwein-Plouffe para calcular los dígitos exactos de Pi. |
| dbcount | Cuenta los registros de vistas de página almacenados en una base de datos. |
| distbbp | Usa una fórmula de tipo BBP para calcular los bits exactos de Pi. |
| grep | Cuenta las coincidencias de una expresión regular en la entrada. |
| join | Realiza una unión de conjuntos de datos ordenados con particiones equiparables. |
| multifilewc | Cuenta las palabras de varios archivos. |
| pentomino | Coloca mosaicos para encontrar soluciones a problemas de pentominó. |
| pi | Calcula Pi mediante un método cuasi Monte Carlo. |
| randomtextwriter | Escribe 10 GB de datos de texto aleatorio por nodo. |
| randomwriter | Escribe 10 GB de datos aleatorios por nodo. |
| secondarysort | Define una ordenación secundaria para la fase de reducción. |
| sort | Ordena los datos escritos por el escritor aleatorio. |
| sudoku | Soluciona sudokus. El archivo de entrada representa el sudoku a resolver. |
| teragen | Genera datos para la ordenación de terabytes (terasort). |
| terasort | Ejecuta la ordenación de terabytes (terasort). |
| teravalidate | Comprueba los resultados de la ordenación de terabytes (terasort). |
| wordcount | Cuenta las palabras de los archivos de entrada. Parámetros: - Ruta del fichero a contar - Directorio de salida donde se crean los ficheros de salida |
| wordmean | Calcula la longitud media de las palabras de los archivos de entrada. |
| wordmedian | Calcula la mediana de la longitud de las palabras de los archivos de entrada. |
| wordstandarddeviation | Calcula la desviación estándar de la longitud de las palabras de los archivos de entrada. |
Ejercicios ✏️
Section titled “Ejercicios ✏️”1. Cuenta las veces que aparece la palabra “allowed” en los ficheros de configuración de hadoop.
Los ficheros de configuración de hadoop son archivos XML, busca todos los archivos y copialos en una carpeta, por ejemplo: /tmp/ejercicio1
2. Resuelve el siguiente sudoku:
8 5 ? 3 9 ? ? ? ?? ? 2 ? ? ? ? ? ?? ? 6 ? 1 ? ? ? 2? ? 4 ? ? 3 ? 5 9? ? 8 9 ? 1 4 ? ?3 2 ? 4 ? ? 8 ? ?9 ? ? ? 8 ? 5 ? ?? ? ? ? ? ? 2 ? ?? ? ? ? 4 5 ? 7 8Pista: jar tf hadoop-mapreduce-examples-3.3.6.jar | grep -i sudoku
3. Cuenta las palabras del libro “Romeo y Julieta”
Ejemplo:
Posibles Errores
Section titled “Posibles Errores”ERROR 1 Si el directorio /tmp/salida ya existe dará error, hay que borrarlo en cada ejecución o cambiarlo
ERROR 2 Cannot execute /home/debian/hadoop-3.2.3//libexec/hadoop-config.sh** En .bashrc hemos añadido una barra al final de HADOOP_HOME Modificar archivo, guardar cambios y luego ejecutar: source .bashrc (para que los cambios se apliquen a la sesión)
ERROR 3 ERROR: JAVA_HOME /usr/lib/jvm/java-17-openjdk-amd64 does not exist La variable de sesión JAVA_HOME no es correcta, revisa la carpeta de java